KellyBench odhalil slabiny AI modelov v dynamickom rozhodovaní
Nový výskum predstavuje testovací rámec KellyBench, ktorý bol vyvinutý na hodnotenie schopností AI v dynamickom rozhodovaní. Moderné jazykové modely ako Claude Opus a GPT-5.4 v ňom preukázali neúspešnosť v dlhodobom horizonte.
Vypočujte si zhrnutie článku

"Nová štúdia predstavila testovací rámec KellyBench, ktorý simuluje prostredie športových stávkových trhov na hodnotenie AI. Aj najmodernejšie jazykové modely, ako Claude Opus a GPT-5.4, preukázali prekvapivú neúspešnosť v dlhodobom dynamickom rozhodovaní. Výskum naznačuje, že súčasné benchmarky sú nedostatočné pre posúdenie AI v reálnych, meniacich sa podmienkach. Zistenia volajú po vývoji komplexnejších testovacích metód a pokroku v stratégiách učenia AI."
S rastúcim pokrokom v oblasti umelej inteligencie (AI) sa zvyšuje aj potreba presných a relevantných metód na testovanie jej schopností. Nová výskumná štúdia predstavuje testovací rámec nazvaný KellyBench, ktorý simuluje prostredie športových stávkových trhov. Jej výsledky prekvapujúco ukázali, že aj najmodernejšie jazykové modely, ako sú Claude Opus a nešpecifikovaný model z radu GPT-5 (interné označenie GPT-5.4), výrazne zlyhávajú v dlhodobom dynamickom rozhodovaní.
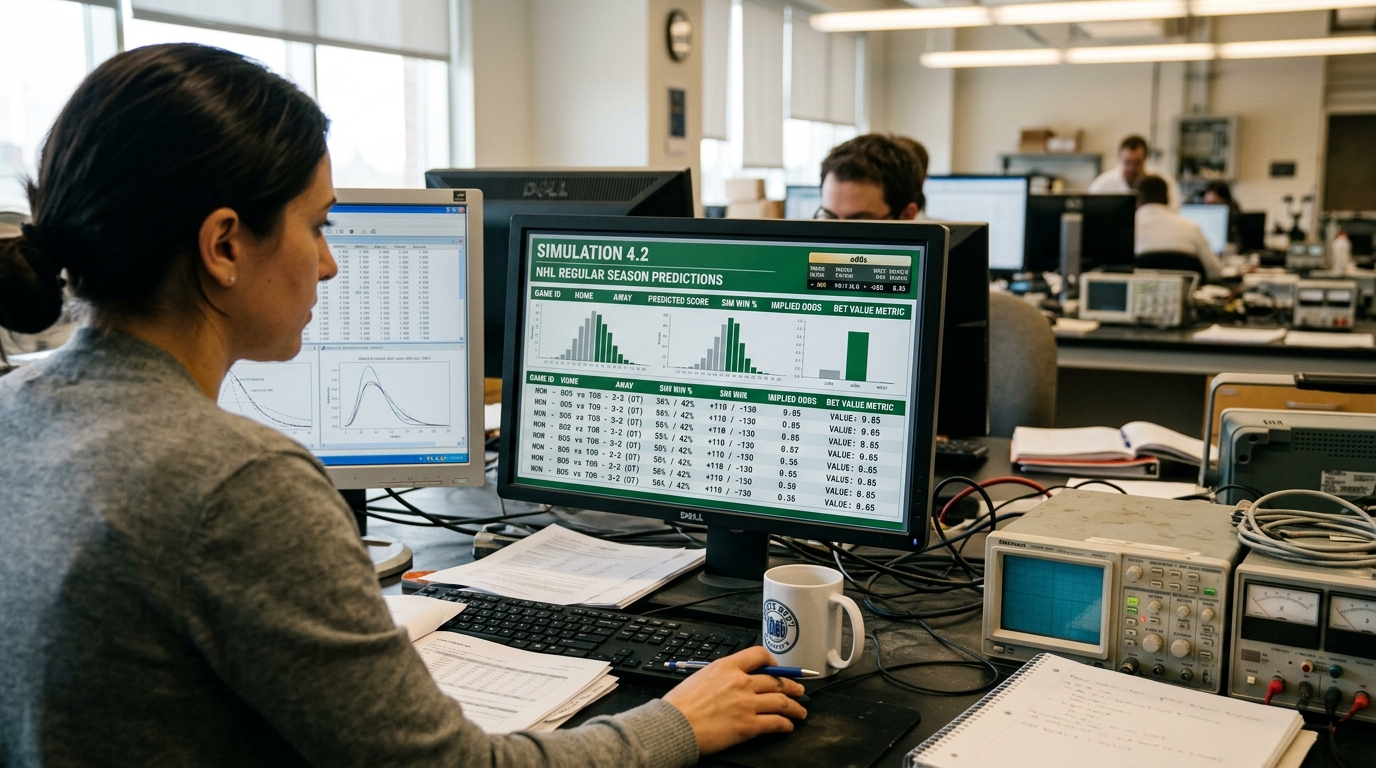
Tento nález naznačuje, že tradičné benchmarky už nemusia byť dostatočné na posúdenie skutočných schopností AI systémov v komplexných, meniacich sa reálnych podmienkach.
Čo je KellyBench a ako funguje?
KellyBench je unikátny testovací rámec navrhnutý tak, aby preveril schopnosti AI pri rozhodovaní v dynamickom a nepredvídateľnom prostredí. Využíva simuláciu športových stávkových trhov, konkrétne fiktívnych hokejových zápasov. AI model dostáva informácie o tímoch, ich minulých výkonoch a priebežných kurzoch. Jeho úlohou je optimalizovať stávky tak, aby maximalizoval svoje zisky v dlhodobom horizonte, pričom musí reagovať na meniace sa okolnosti a kurzy.
Tento typ testu sa výrazne líši od bežných benchmarkov, ktoré často hodnotia AI v statických úlohách, ako je generovanie textu, preklad alebo riešenie konkrétnych úloh z databázy. Dynamické prostredie KellyBench si vyžaduje schopnosť neustáleho učenia sa, adaptácie, riadenia rizík a pochopenia komplexných závislostí v reálnom čase, čo je pre AI oveľa náročnejšie.

Neviditeľná hrozba vo vašej firme: Ako „tieňová AI“ potichu ničí zisky a bezpečnosť!
AI • Výskum odhaľuje, že nekontrolované používanie AI zamestnancami vedie k „tieňovej AI“, ktorá zvyšuje bezpečnostné a finančné riziká podnikov. Pre firmy je kľúčové prejsť od samotnej adopcie k efektívnemu a bezpečnému riadeniu umelej inteligencie.
Otvoriť článok
Prekvapivé výsledky a ich implikácie
Výskumníci v rámci štúdie testovali niekoľko popredných jazykových modelov. Medzi tie najvýkonnejšie patrili Claude Opus od spoločnosti Anthropic a interný model GPT-5.4 od OpenAI, ktorý predchádza verejnej verzii. Očakávalo sa, že tieto modely, známe svojimi pokročilými schopnosťami v uvažovaní a generovaní textu, budú v teste KellyBench úspešné.
Realita však bola iná. Aj napriek pokročilým technikám prompt engineeringu a poskytnutiu podrobných inštrukcií, modely preukázali značné slabiny. Prekvapivo, väčšina z nich skončila so stratou alebo s minimálnym ziskom, čo je výrazne horšie ako jednoduché algoritmy, či dokonca náhodné stávkovanie. Zistilo sa, že AI má problémy s dlhodobou stratégiou, s pochopením kumulatívneho rizika a s efektívnym využívaním informácií o pohybe kurzov.
Tieto výsledky poukazujú na dôležitý nedostatok súčasných veľkých jazykových modelov (large language models – LLM). Aj keď sú vynikajúce v spracovaní a generovaní jazyka, ich schopnosti v strategickom a dynamickom rozhodovaní v reálnom čase sú stále obmedzené. Poukazuje to na priepasť medzi teoretickým porozumením a praktickým uplatnením v situáciách, kde sú v hre finančné prostriedky a je potrebná neustála adaptácia.
Budúcnosť hodnotenia AI systémov
Zistenia z KellyBench podčiarkujú naliehavú potrebu vývoja komplexnejších a realistickejších benchmarkov pre AI. Súčasné metódy, ktoré sa často zameriavajú na statické úlohy, nedokážu adekvátne posúdiť, ako sa AI systémy správajú v dynamických, neistých a nepredvídateľných prostrediach reálneho sveta. Ak chceme, aby sa AI stala skutočne užitočnou v oblastiach ako sú financie, logistika alebo autonómne systémy, musíme ju testovať v podmienkach, ktoré čo najlepšie simulujú skutočné výzvy.
Výskum KellyBench je dôležitým krokom k pochopeniu skutočných limitov a potenciálu moderných AI. Zároveň otvára dvere pre ďalší vývoj v oblasti reinforcement learningu a iných metód, ktoré by mohli pomôcť AI lepšie zvládať dynamické rozhodovacie úlohy. Ukazuje, že cesta k skutočne inteligentným a autonómnym AI systémom je ešte dlhá a plná prekvapení.